Summary of Elasticsearch used at my work
ES优化方案
ES调研:
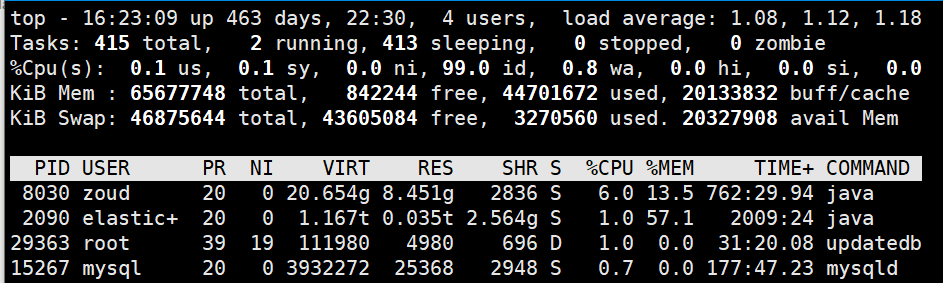
1. 以192.168.130.21为例,目前elastic服务占用服务器35.76GB(57.1%)的内存
![1]()
堆内存:大小和交换 | Elasticsearch: 权威指南 | Elastic
服务器是62GB,MySQL占用8.4GB,官方建议给ES分配的内存为可用内存的50%(27GB),给Lucene缓存服务留下更多的内存
![2]()
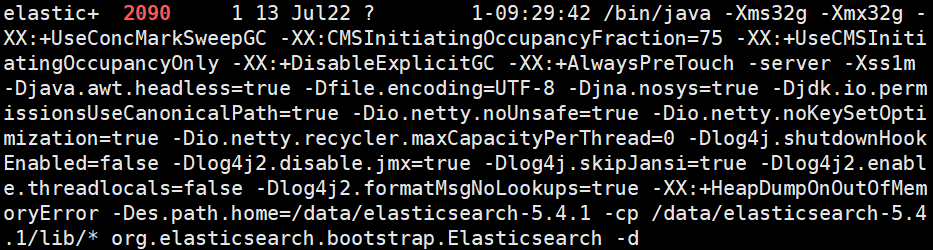
从图里看,目前给elastic服务设置的堆内存是32GB,超过27GB,
堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好。
官方举了个例子,给64GB服务器分配32GB内存到ES上恰好存在一个内存指针压缩的问题,最稳妥的是分配31GB内存。
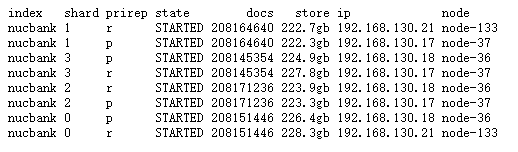
2. 现有4个主分片+4个副本分片,每个分片大概225gb
- 官方社区建议每个分片尽量控制在10-50GB
![3]()
优化建议一:分成45个分片,以现有数据规模900GB来看,每个分片大概保留20GB的数据
结论:先分成30个分片
3. 首页不提供全局搜索,只展示静态页面,和NCBI相似,用户输入内容后才显示搜索内容
4. 分库分表先不操作,代码改动比较大
5. 聚合的操作需要单独进行优化
提升导入性能
牺牲数据可靠性及搜索实时性以换取数据写入性能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| {
"settings": {
"index": {
"refresh_interval": "-1",
"number_of_shards": "30",
"number_of_replicas": 0,
"translog": {
"sync_interval": "60s",
"durability": "async"
},
"routing": {
"allocation": {
"total_shards_per_node": 15
}
},
"mapping": {
"total_fields":{
"limit": 2000
}
}
},
"mapper": {
"dynamic": false
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| PUT http:
"index": {
"refresh_interval": "-1",
"number_of_shards": "30",
"number_of_replicas": 0,
"mapping.total_fields.limit": "2000",
"translog": {
"sync_interval": "60s",
"durability": "async"
},
},
"routing": {
"allocation": {
"total_shards_per_node": 15
}
},
"mappings": {
"dynamic": false
}
bootstrap.memory_lock: true
{
"settings": {
"index": {
"refresh_interval": "-1",
"number_of_shards": "30",
"number_of_replicas": 0,
"translog": {
"sync_interval": "60s",
"durability": "async"
},
"routing": {
"allocation": {
"total_shards_per_node": 15
}
},
"mapping": {
"total_fields":{
"limit": 2000
}
}
},
"mapper": {
"dynamic": false
}
}
}
{
"settings": {
"index": {
"refresh_interval": "60s",
"number_of_replicas": 1,
"translog": {
"sync_interval": "60s",
"durability": "async"
}
}
}
}
|
1
2
3
4
| PUT http://192.168.130.21:9200/nucbank1/_settings
{
"index.mapping.total_fields.limit": 2000
}
|
导入数据完成后执行http://192.168.130.21:9200/nucbank1/_refresh
使用_bulk批量导入数据
测试环境:POST http://192.168.130.19:9200/seqbank/nucleotide/_bulk
正式环境:POST http://192.168.130.21:9200/nucbank/nucleotide/_bulk
使用:
1
2
| { "index": {}}
{ "accession": "", "definition":"" }
|
不要使用:
1
2
3
4
| {"index": {"_index": "nucbank", "_type": "nucleotide", "_id": 1}}
{"doc": {"accession": "", "definition":""}}
{"index": {"_index": "nucbank", "_type": "nucleotide", "_id": 2}}
{"doc": {"accession": "", "definition":""}}
|
注意在 json 文件末尾加多一个回车
kibana
192.168.164.19